CNN Architecture
In our last article, we talked about Multilayer Models in PyTorch, in case you didn’t know that, I highly recommend you to read our last article. Now, we are going to talk about CNN (Convolutional Neural Network).
Summary:
- Convolutional Layers
1.1. How Does It Work?
1.2. Techniques Used in Convolutional Layers
1.3. How Does It Learns? - Understanding a CNN (Convolutional Neural Network)
2.1. What is a CNN?
2.2. CNN Architecture - CNN in PyTorch
3.1. Model Architecture
3.2. Training the Model
3.3. Loss and Accuracy
4. Conclusions
5. References
1. Convolutional Layers
To understand what is a Convolutional Neural Network, first we need to understand what is a convolutional layer.
A convolutional layer is a very good layer to work with images.
An image, in machine learning, is usually represented as a matrix. Each pixel is a value between 0–1 in the matrix.
An RGB image have 3 channels, one for red, green, and blue

An RGB image, of 16px by 16px pixels, can be represented as a matrix of shape:
(3 x 16 x 16)
1.1 How Does It Work?
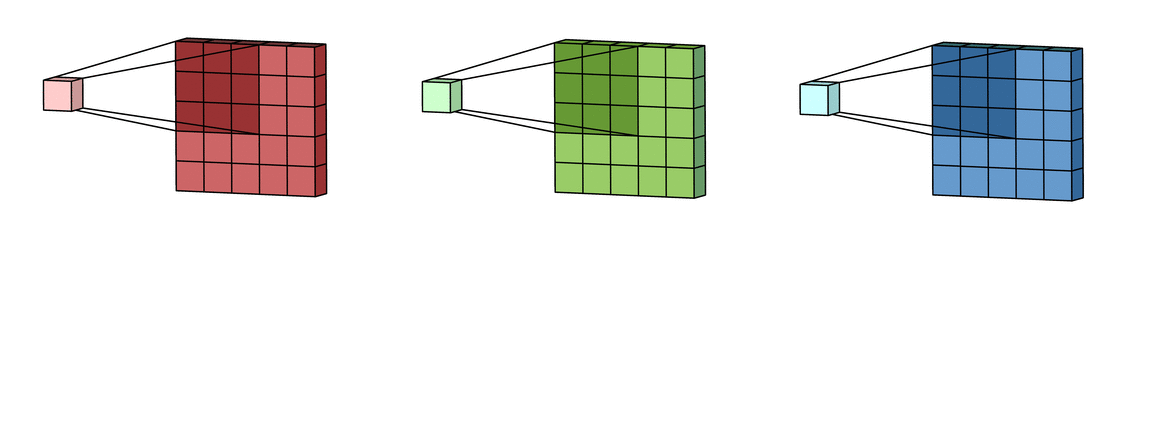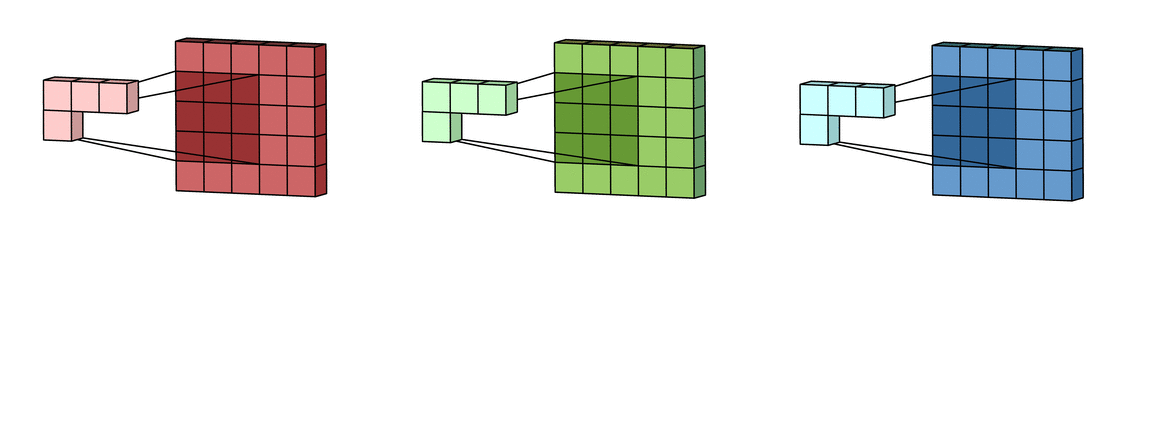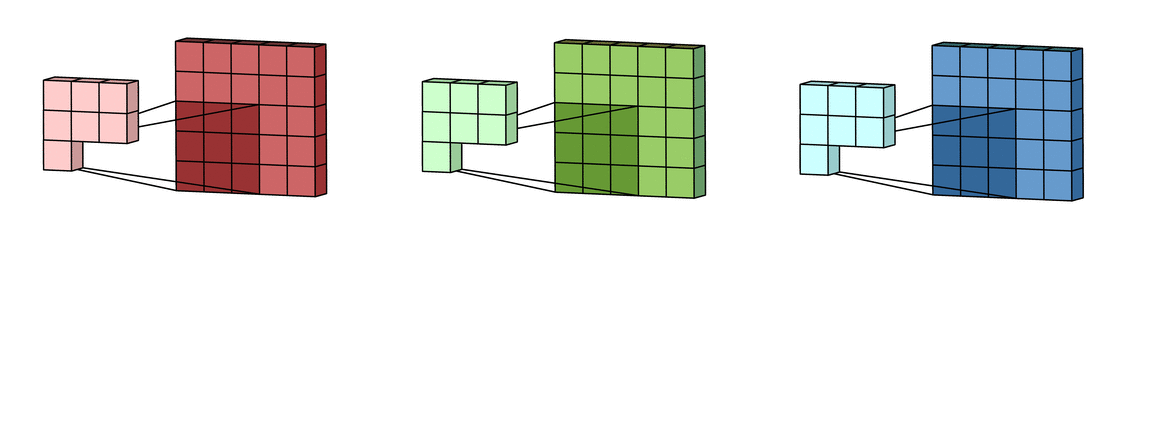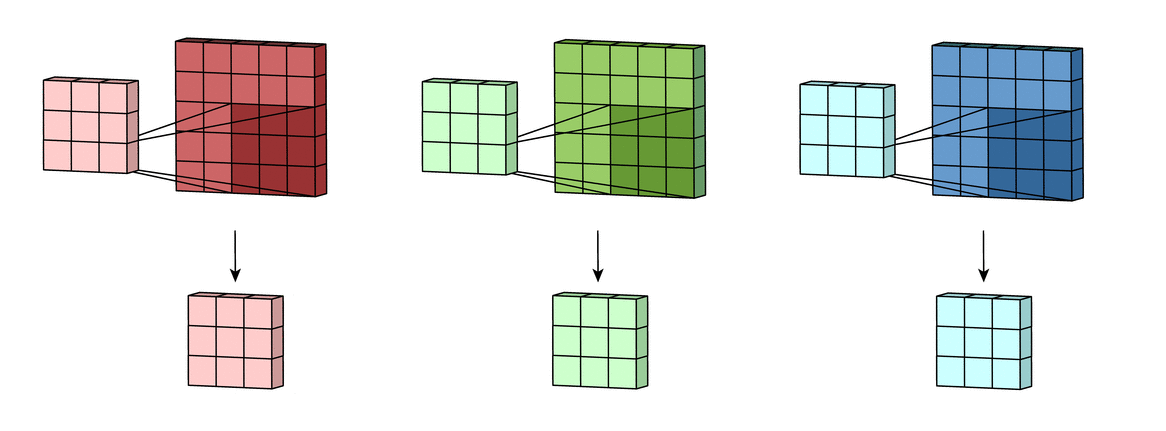
The 2D convolution is a fairly simple operation at heart: you start with a kernel, which is simply a small matrix of weights. This kernel “slides” over the 2D input data, performing an elementwise multiplication with the part of the input it is currently on, and then summing up the results into a single output pixel. — Source
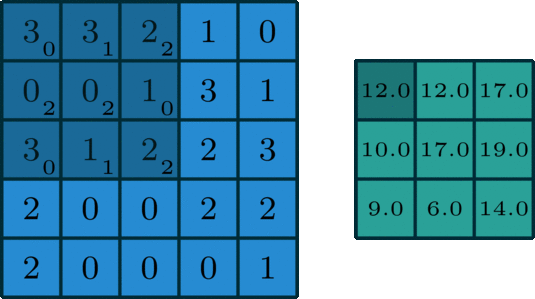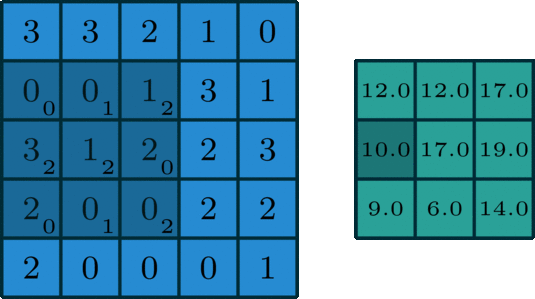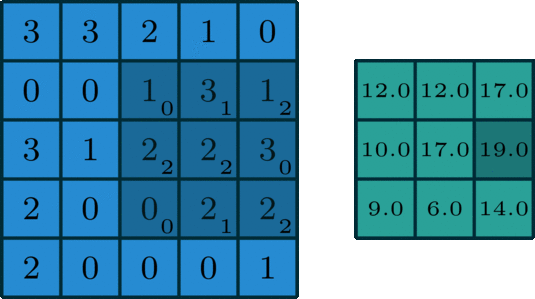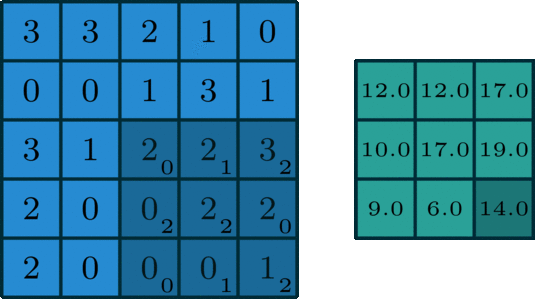
The convolutional layer kernel (filter) often has a 3 by 3 format, but this shape can vary from model to model, all parameters on that kernel can be learnable. A convolutional layer can have thousands of filters, depends on the depth of the layer and how much memory you have.
A convolutional layer frequently increases the image channels, and there is a kernel for each image channel.
1.2. Techniques Used in Convolutional Layers
There are some techniques used in convolutional layers, like padding and striding.
- Padding: Pad the image edges with “fake” pixels, so the output will be the same size as the input. The fake pixels typically have value 0, but it can also have the same value as the edge pixels.
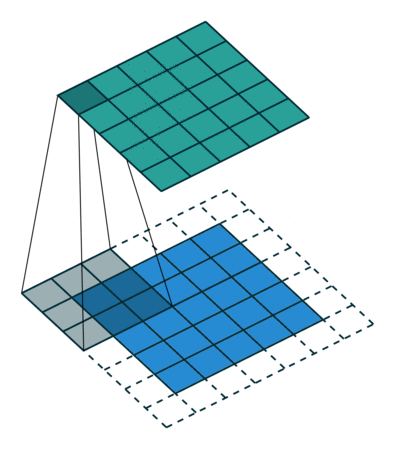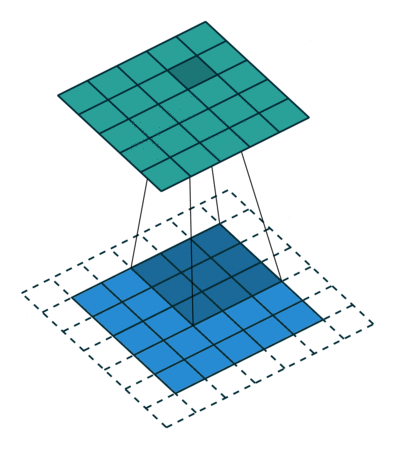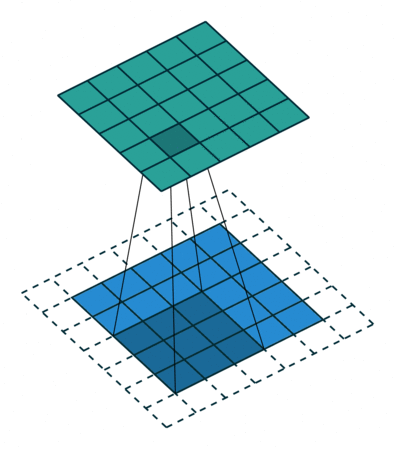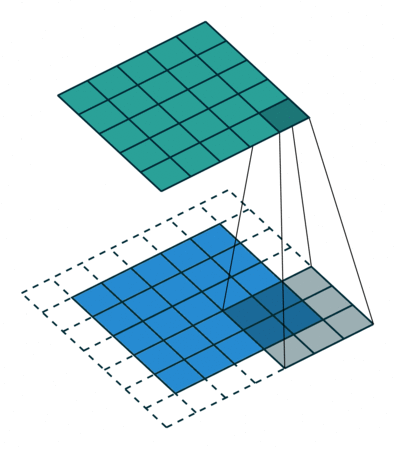
- Striding: Stride is how many pixels the kernel must move through the image. In this example, the kernel is moving 2 pixels at a time. This technique is used to reduce the size of the output.

Another alternative instead of using stride is to use a pooling layer, which will decrease the image width and height, but recent neural networks don’t use pooling layers.

1.3. How Does It Learns?
Every filter is responsible to learn some aspect of the images in the train dataset.

With linear regression, the convolutional layers can learn from the images.
As you go deeper through the network, the filters will learn more complex things, example: the filters from the first layer will learn to recognize edges, and circles, filters on the second layer will learn to recognize eyes, mouths, eyebrows, and noses, and filters on the third layer will learn to recognize faces.
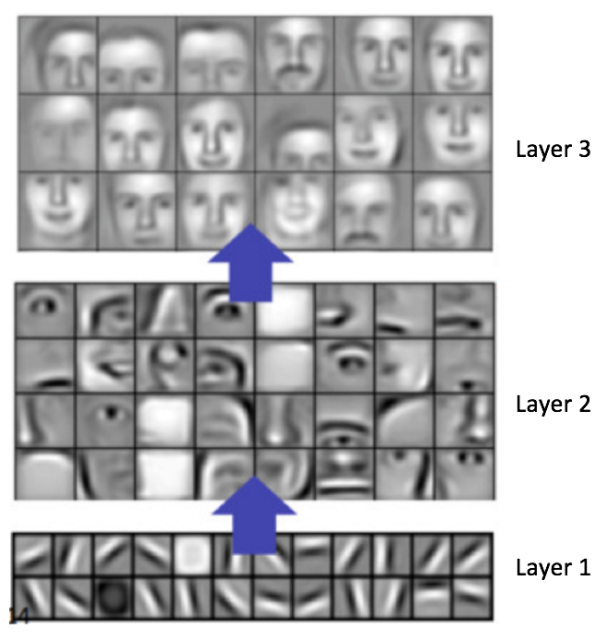

You can’t define or predict what each filter on each layer will learn, because the initial random parameters will decide this.
You can use a technique called filter visualization to see what your convolutional layers are learning, but we aren’t going to see this technique here.
If you want to know more about convolutional layers, I recommend you read these articles:
For convolutional layer:
- Convolution in Depth (Convolutional layers from scratch)
- Intuitively Understanding Convolutions for Deep Learning
- Watch This Neural Network Learn to See
Pooling layer:
2. Understanding a CNN (Convolutional Neural Network)
2.1. What is a CNN?
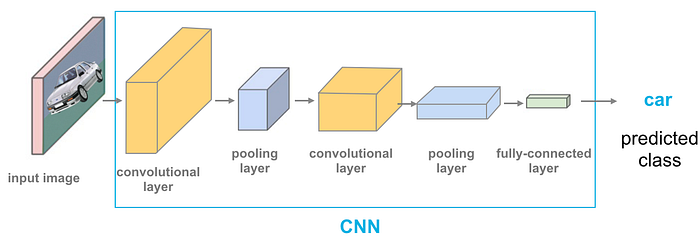
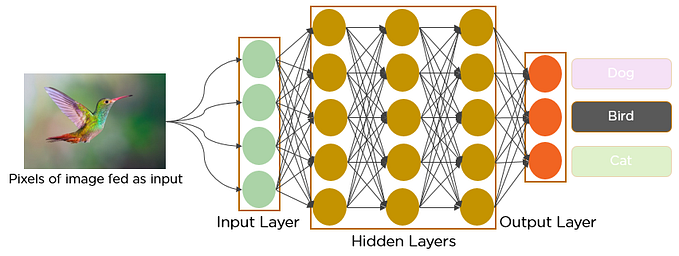
A CNN basically is a neural network composed by convolutional layers that reduces an image to a vector.
There are a many applications, such as image segmentation, image classification, image generation, etc.
2.2. CNN Architecture
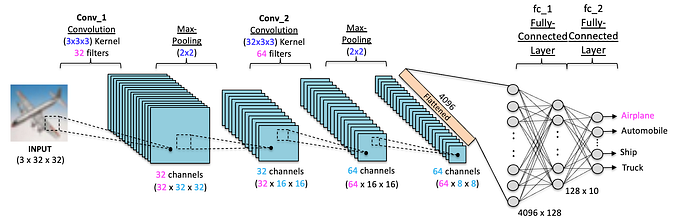
The CNN model architecture is pretty simple.
We insert an image into the model, then decrease the image and increase the image channels, which are called feature maps. By increasing the feature maps and decreasing the image, the model can learn to recognize patterns in the images. After reducing the image size to a very low size, the image will have a lot of feature maps, and then we just pass the feature maps to a feed forward layer (linear layer) to generate the probabilities.
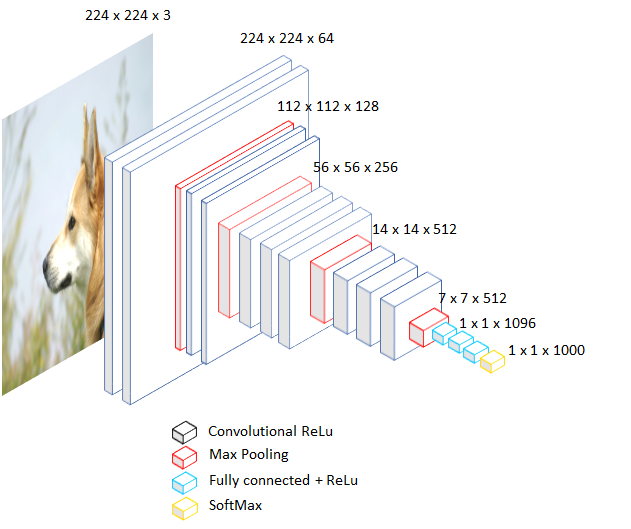
Lets took this architecture above as example.
First, it will take a 224 by 224 pixels RGB image, will increase the feature maps with convolutional layers, then the data will be activated, with a ReLU function. The image size will be halved, and the model will repeat these steps until the image is 7 by 7 pixels, which is an odd number. Then, the image will go through linear layers with activations, and then the softmaxed. The output will be a vector of size 1000, that each value is probabilitie of one of 1000 classes.
The CNN we are going to build will use 3 blocks containing convolutional layers and ReLU, because we want to decrease the image size and increase the image channels. In the end, we have a convolutional layer to decrease the image size from 7 by 7 to 1 pixel using a kernel of size 7. This final convolutional layer doesn’t require an activation, and we flatten the data to only 1 dimension and then use a fully connected layer to output 10 probabilities.
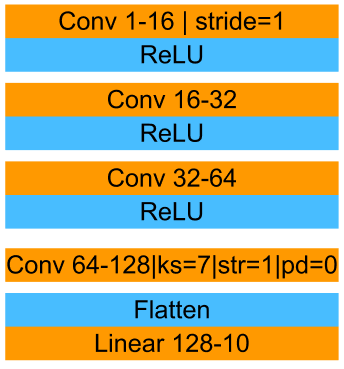
3. CNN in PyTorch
Now that we understand how it works and learns, let's build our own CNN.
Let’s starting importing the data, creating the project configuration, helper functions and creating the data loader.
3.1. Model Architecture
Now we will create our simple CNN model.
We set the bias to false, to improve our model performance
3.2. Training the Model
Let’s define our loss function and our optimizer. As loss function, we will use cross entropy, and as optimizer we will use SGD, like our last model, and let’s train our model.
3.3. Loss and Accuracy
Let’s check our model loss and accuracy:
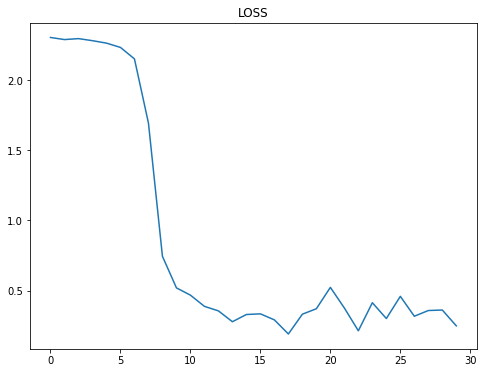

In just 30 epochs we got accuracy of 91%, different from our last model we got 90% of accuracy in 40 epochs. This CNN model is slightly better than a model with linear layers, but we can do this model more powerful with 98% of accuracy, using simple techniques, that we are going to see in the next article.
4. Conclusions
So convolutional layers have filters that usually are size 3 by 3, this filter slides over the image features to learn representations.
Convolutional Neural Networks are pretty simple, just reduces the image size and increase the image feature maps, and doing this the model can learn to recognize patterns on images.
This model is slightly better than our previous model, but in our next article, we will learn to improve this model to 98% of accuracy.
And here are the full code:
Thanks for reading this article, if you have any questions, feel free to comment!!